From Local Terraform to CI: Structuring Shared and Nonprod Stacks for GKE

By the end of the previous step, the cluster had a defined shape.
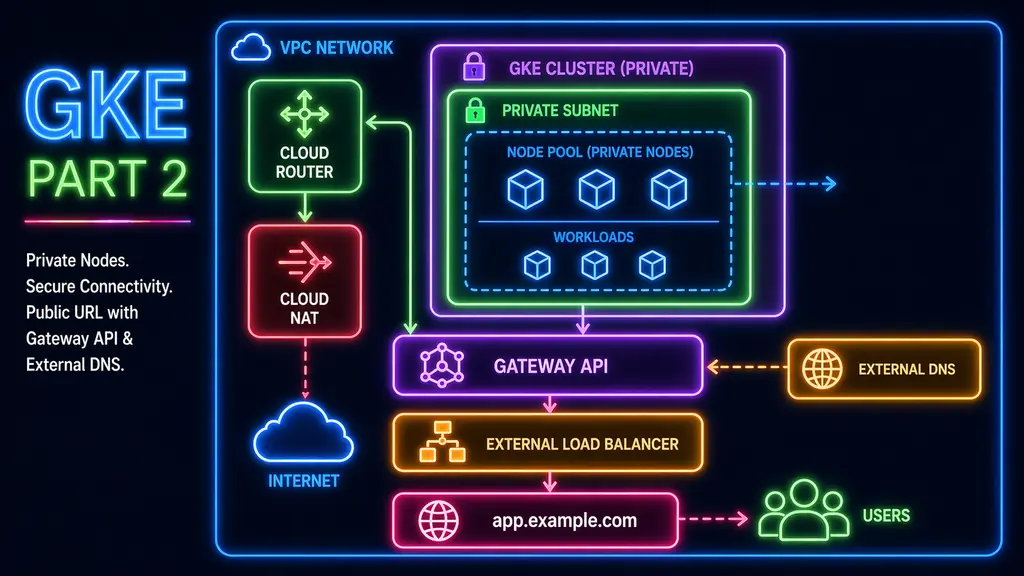
Nodes were private, outbound traffic was routed through NAT, and inbound traffic flowed through a Gateway instead of individual services. A hostname pointed to that Gateway, and a simple workload confirmed that the path from DNS to container was working.
That was enough to validate the cluster itself.
What was still missing was how the rest of the system should be organized so that it could be applied consistently, and not just from a single laptop session.
From local execution to CI
Up to this point, Terraform was being run locally using Application Default Credentials.
That worked, and it was the simplest way to get started. But it also meant that:
- the ability to apply infrastructure depended on a local environment
- permissions were tied to a human user rather than a defined role
- there was no clear boundary between shared resources and environment-specific ones
The cluster was working, but the system around it was not yet structured in a way that could be reused or operated by something other than a local session.
The next step was to move Terraform execution into CI and make the structure explicit.
Structuring shared and nonprod stacks
As more components were added, especially DNS and artifact storage, it became clear that not everything belonged to the same environment.
Some resources are naturally shared:
- DNS zones
- artifact registries
Others are tied to an environment:
- project services
- networking
- the GKE cluster
The separation between shared and non-production stacks was not just about organization. It defined ownership and made it clear which resources could be reused across environments and which ones could change independently.
The structure reflects that:
Manual bootstrap
|
+-- state buckets
+-- Terraform runner service accounts
+-- GitHub OIDC / Workload Identity Federation
Live stacks
|
+-- shared/dns-zone
+-- shared/artifact-registry
|
+-- nonprod/project-services
|
v
nonprod/foundation
|
v
nonprod/gkeEach Terraform root represents a deployable unit with its own state.
This is an extension of the earlier separation between foundation and GKE, but applied more broadly. Instead of treating the system as a single graph, dependencies are made explicit and applied in order.
Keeping bootstrap separate
Bootstrap remains a separate concern.
Terraform needs a backend, service accounts, and identity configuration before it can run reliably. These pieces are created once and change infrequently, so they are applied manually rather than through CI.
This layer includes:
- remote state buckets
- Terraform runner service accounts
- Workload Identity Federation setup
Keeping bootstrap out of CI reduces complexity and makes the dependency chain clearer.
Running Terraform through GitHub Actions
With the structure in place, Terraform execution was moved into GitHub Actions.
Instead of using a service account key, Workload Identity Federation is used so that GitHub can exchange its OIDC token for short-lived credentials. This allows workflows to impersonate a Terraform runner service account without storing long-lived secrets.
A minimal workflow looks like this:
permissions:
id-token: write
contents: read
steps:
- uses: actions/checkout@v4
- uses: google-github-actions/auth@v2
with:
workload_identity_provider: ${{ vars.GCP_WIF_PROVIDER }}
service_account: ${{ vars.GCP_SA_NONPROD }}
- uses: hashicorp/setup-terraform@v3
- run: terraform init -input=false
working-directory: gcp/live/nonprod/foundation
- run: terraform plan -input=false
working-directory: gcp/live/nonprod/foundationEach stack has its own workflow. The logic is the same, but the working directory and service account differ depending on what is being applied.
This changed how Terraform was executed: from a local user session to a service-account-backed workflow.
At this stage, workflows were triggered manually. This made it possible to validate each stack independently before introducing more automation.
Validation through behavior
Validation followed the same approach used earlier with the cluster.
The goal was to observe behavior rather than assume correctness.
On the infrastructure side:
- Gateway routing was verified by sending requests directly to the external IP with a host header
- DNS issues exposed incorrect zone boundaries rather than problems in Kubernetes
- workloads confirmed that networking and image pulls were functioning as expected
On the CI side, initial failures were useful.
Errors such as missing permissions or inability to generate access tokens pointed directly to gaps in IAM configuration. Fixing these clarified which identity was running Terraform and what permissions it required.
Outcome
The system did not gain new features through this change.
Instead, the way it is operated became more defined.
Terraform is no longer tied to a local environment. Each stack has a clear boundary and can be applied independently. Authentication is handled through short-lived credentials rather than stored keys. Shared resources and environment resources are separated in a way that reflects how they are used.
The cluster remains the same.
What changed is how it is managed, and how that management can be repeated without relying on a specific machine or user session.